Advertisement
Most people think image generation with AI is some kind of magic. You type in a few words, and somehow, you get a detailed picture that looks like a person painted it. Stable Diffusion is behind a lot of that. It’s not a one-button tool—it's a whole system with moving parts, and understanding it makes using it easier. Whether you're curious about how it works, want to try it out, or are just wondering why people keep talking about it, this guide provides a clear explanation in plain language.
Stable Diffusion is a type of AI model that turns text into images. It belongs to a family of systems called diffusion models. These models don't just guess an image from scratch. Instead, they start with noise—like TV static—and slowly adjust it until it matches the text input. It's like sculpting out of marble; only the chisel is math, and the sculpture is built pixel by pixel.
The term “diffusion” comes from the way the model learns to reverse noise into structure. During training, the model learns what objects, colors, and shapes typically go together. It’s shown millions of images and learns how to recreate them starting from static. When you prompt it with something like “a cabin in the woods during winter,” it starts from random pixels and nudges those pixels closer to what it believes matches the prompt. This process happens in stages, with each step refining the image a little more.
What makes Stable Diffusion stand out is that it’s open-source. That means developers and artists can use it freely, modify it, and build tools on top of it. It’s not locked behind a company’s paywall. It can run on personal machines and is light enough that people don’t need massive computing clusters to try it out. That’s a big reason why it’s everywhere—from small art projects to commercial tools.
The core of Stable Diffusion lies in how it combines different models and techniques. It starts with a text encoder, usually something like CLIP from OpenAI. That part turns the words you type into a language map—a digital representation of what the prompt means. Next comes the U-Net, which works with noise and helps shape that noise into a meaningful image. This is where the diffusion happens: starting with a blurry mess and improving it in steps.
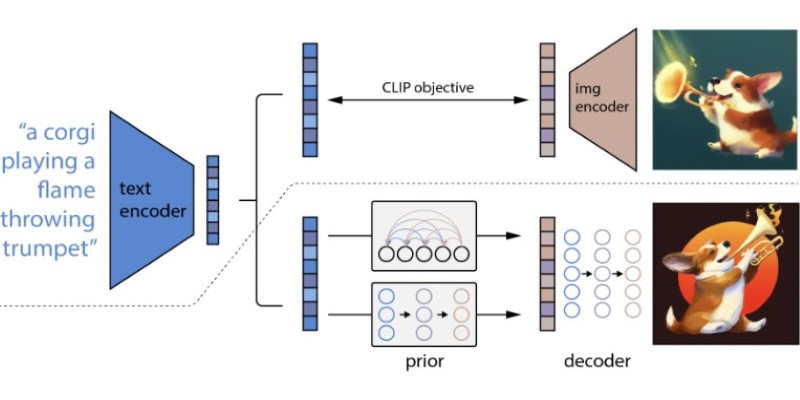
There’s also something called a “latent space,” which is a fancy way of saying compressed image data. Instead of working on full-sized images, Stable Diffusion turns everything into a smaller version that’s faster to process. It applies the diffusion steps to this smaller version, then uses another model (called a decoder) to turn it back into a normal image. This technique saves time and hardware power while still delivering detailed results.
Training Stable Diffusion required access to massive image-text datasets. The AI had to look at billions of image-prompt pairs to learn the links between visual elements and language. Once trained, it doesn’t "remember" specific images but understands the general idea of what things look like. This lets it mix concepts in strange and creative ways. That’s why you can generate something like “a fox in a spacesuit walking on the moon,” and it comes out looking surprisingly coherent.
The uses of Stable Diffusion are growing fast. At the most basic level, people use it for fun—to create art, avatars, or surreal scenes. Since it’s open-source, communities have developed extensions that allow users to customize images deeply. You can adjust how much freedom the model has, guide its creativity with reference images, or tweak specific features using inpainting (fixing or altering parts of an image).
It’s not just artists using it. Designers use it to draft ideas quickly. Authors use it to generate concept art for characters or scenes. Marketing teams use it to build visuals for products. In education, teachers can use it to make visual aids that explain concepts that are hard to draw by hand. The ability to turn a few words into something visual opens up new options across industries.
A major reason for its popularity is control. Tools built on Stable Diffusion let users adjust how close or far the final result sticks to the original text. That’s useful when you're not aiming for randomness. People can guide it to focus on color, shape, or detail, depending on the need. It can also be chained with other models—like those that improve resolution or clean up artifacts—to produce results that look polished and ready for use.
Stable Diffusion isn’t perfect. It struggles with hands, text, and fine detail unless guided carefully. It may also reflect biases from its training data. If certain styles, cultures, or groups are overrepresented or underrepresented, the outputs can feel skewed. That’s why people are fine-tuning the model for fairness and balance.

Misuse is another concern. Since it can create realistic images, there’s a risk of generating false visuals or deepfakes. Some communities have responded by setting ethical guidelines or filters to block certain content. Others have built watermarking systems or detection tools to trace origins. But it’s a moving target, and open-source access means anyone can adjust or remove those limits.
Copyright is also under debate. If the AI was trained on artwork scraped online, does the final image count as “original”? This raises issues for artists, companies, and regulators. Courts and policies are still catching up. People using Stable Diffusion for work should stay cautious and informed.
Despite all this, Stable Diffusion keeps improving. New versions bring better detail, faster generation, and more control. The open community keeps pushing it forward.
Stable Diffusion has shifted how we see AI and creativity. It's more than a tool—it turns words into images using a process built on open technology. Artists, developers, and everyday users are exploring its potential. While it raises questions about ethics and accuracy, it's already proving useful in many areas. Understanding how it works makes it easier to use responsibly and creatively, giving anyone a clear window into AI-generated art.
Advertisement

How the semi-humanoid AI service robot is reshaping commercial businesses by improving efficiency, enhancing customer experience, and supporting staff with seamless commercial automation
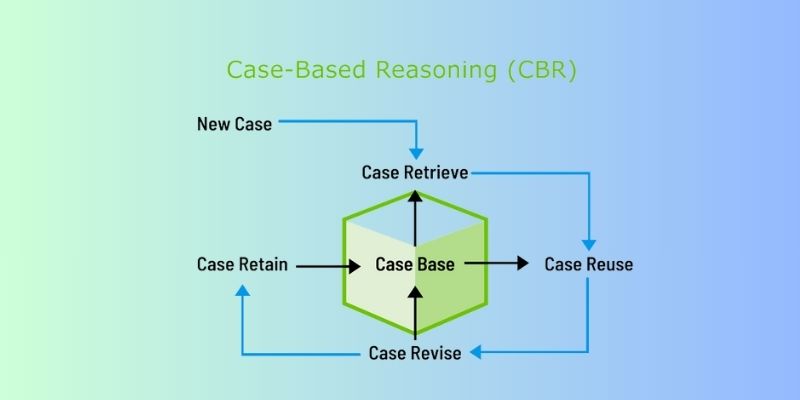
Discover how Case-Based Reasoning (CBR) helps AI systems solve problems by learning from past cases. A beginner-friendly guide

Discover how AI in the construction industry empowers smarter workflows through Industry 4.0 construction technology advances

Learn everything about Stable Diffusion, a leading AI model for text-to-image generation. Understand how it works, what it can do, and how people are using it today

Llama 3.2 brings local performance and vision support to your device. Faster responses, offline access, and image understanding—all without relying on the cloud
How the Adam optimizer works and how to fine-tune its parameters in PyTorch for more stable and efficient training across deep learning models
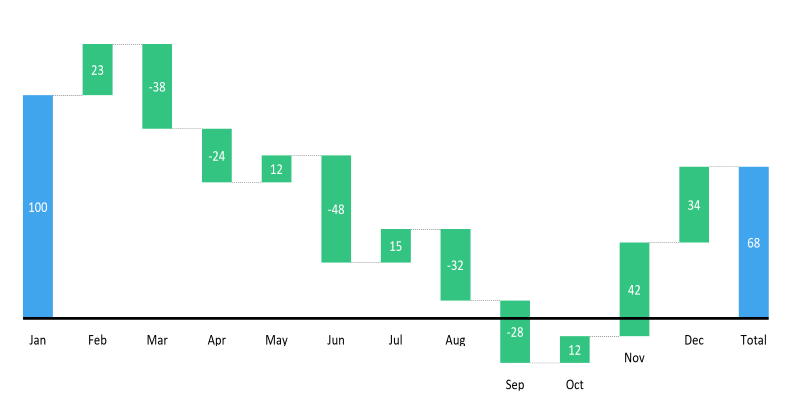
Learn how to create a waterfall chart in Excel, from setting up your data to formatting totals and customizing your chart for better clarity in reports

Artificial intelligence accurately predicted the Philadelphia Eagles’ Super Bowl victory while a quantum-enhanced large language model launched, showcasing AI’s growing impact in sports and technology

What happens when robots can feel with their fingertips? Explore how tactile sensors are giving machines a sense of touch—and why it’s changing everything from factories to healthcare

Beginner's guide to extracting map boundaries with GeoPandas. Learn data loading, visualization, and error fixes step by step
How Hugging Face Accelerate works with FSDP and DeepSpeed to streamline large-scale model training. Learn the differences, strengths, and real-world use cases of each backend

Understand how GPT's decoder-only transformer works, its advantages, challenges, and why it is transforming the future of AI