Advertisement
Most AI models aim to impress with size—more data, more parameters, more claims. Orca LLM takes a quieter path. Instead of growing bigger, it learns smarter. Built by Microsoft Research, this model doesn’t just generate answers; it mirrors how experts think. That small shift—learning from the reasoning of stronger models—makes a big difference.
Orca isn't built to dazzle with volume but to stand out through clarity and logic. It’s the kind of tool that values thought over flash, showing what happens when training focuses on explanation instead of output. In a field chasing scale, Orca chose something sharper: structure.
Orca LLM was introduced by Microsoft Research as a student model designed to learn from more capable teacher models. Instead of relying on massive training datasets alone, Orca was trained to observe, mimic, and adopt the thinking steps of expert models like GPT-4. The goal wasn’t just to get the right answer—it was to understand how expert models arrive at it. This step-by-step imitation of reasoning is what gives Orca its edge.
Most models are trained on massive corpora and then fine-tuned with reinforcement learning. Orca, however, was trained using a method called explanation tuning. This process involved feeding the model not only the answer but also the chain-of-thought reasoning from a larger, more advanced model. This way, Orca wasn't just guessing—it was being taught how to think through problems logically.
This approach allowed a smaller model to match or even exceed the performance of larger models in certain reasoning tasks. By leaning into reasoning and structure, Orca managed to shrink the gap between model size and performance. It showed that good thinking could beat raw size. This philosophy brings a different flavor to the AI world—one that values clarity over brute strength.
Explanation tuning is at the heart of Orca LLM's training method. Think of it as watching a tutor solve a math problem, not just seeing the final answer. Instead of being told "42," Orca is shown every logical step that led to it. This matters because most language models are pattern matches at heart—they mimic what they've seen without always understanding why it works. Orca flips this.

The process begins by generating detailed answers from a teacher model, which includes not just conclusions but the reasoning paths taken. These paths are then used to train Orca. The model learns that there's a difference between guessing and deducing. Over time, it internalizes those reasoning templates. So, when Orca faces a new question, it doesn’t just respond—it tries to think like its teacher.
This style of learning not only improves answer accuracy but also makes the model more transparent. When prompted, Orca can produce its thought process, helping users follow its reasoning. That's a big step forward in explainability, something that black-box models often struggle with.
Orca LLM doesn’t try to be everything. It doesn’t aim to write poetry or summarize the news with flair. Where it shines is in structured reasoning tasks—math word problems, logic puzzles, multi-step question answering, and more formalized domains like science and engineering. In benchmarks like GSM8K and Big-Bench Hard, Orca consistently outperformed larger models because of its focused training.
Another area where Orca stands out is education. Since it mimics the reasoning steps of expert models, it can act as a tutor. Instead of just giving a student the right answer, Orca can show the thought process in a way that’s easy to follow. This helps users not just get answers but learn the method. It’s a shift from task completion to skill building.
In customer support or technical troubleshooting, Orca’s clarity also helps. A model that walks through its reasoning can better justify its answers and adjust when asked clarifying questions. This kind of back-and-forth reasoning is harder to pull off with models trained only on outcomes, not process.
Even in legal and compliance fields, where step-by-step logic is crucial, Orca offers potential. Its ability to provide traceable answers makes it a better fit for scenarios where mistakes carry more weight.
Orca LLM doesn’t just introduce a model—it introduces a mindset. The idea that smaller models can perform well if taught properly challenges the arms race in AI model size. This doesn’t mean big models are obsolete, but it shifts attention to how models are trained, not just how big they are.

The rise of Orca suggests that hybrid training approaches—where smaller models learn from the outputs and reasoning of larger ones—might become the new normal. This offers a path forward for companies without massive computing budgets. It means smaller teams can build smarter models, not just bigger ones.
It also opens doors for domain-specific applications. Instead of building one monolithic AI, developers might create a fleet of Orca-like models, each trained to reason well in one area—medicine, law, finance, etc. With explanation tuning, these models wouldn’t just specialize in language; they’d specialize in thinking.
Another long-term impact lies in transparency. As regulators and the public push for more explainable AI, models trained with visible reasoning processes will become more attractive. People don’t just want correct answers—they want to know how those answers were reached. Orca moves in that direction.
Orca’s smaller size means it runs faster and uses fewer resources, making it more efficient than larger models. This opens the door to deploying advanced LLMs on edge devices, reducing dependence on the cloud and offering better solutions for low-connectivity regions or environments with strict privacy requirements.
Orca LLM shows that there’s more than one way to build intelligence. Instead of scaling up endlessly, it stepped sideways and rethought how a model could learn. By focusing on explanation tuning and mimicking reasoning, it created a blueprint for more efficient, more transparent language models. Orca might not replace the giants of AI, but it proves that understanding can sometimes beat size. It’s not the loudest model in the room, but it might be the one that makes the most sense. That shift—from output to process—could be where the future of language models heads next.
Advertisement

Looking for a reliable and efficient writing assistant? Junia AI: One of the Best AI Writing Tool helps you create long-form content with clear structure and natural flow. Ideal for writers, bloggers, and content creators
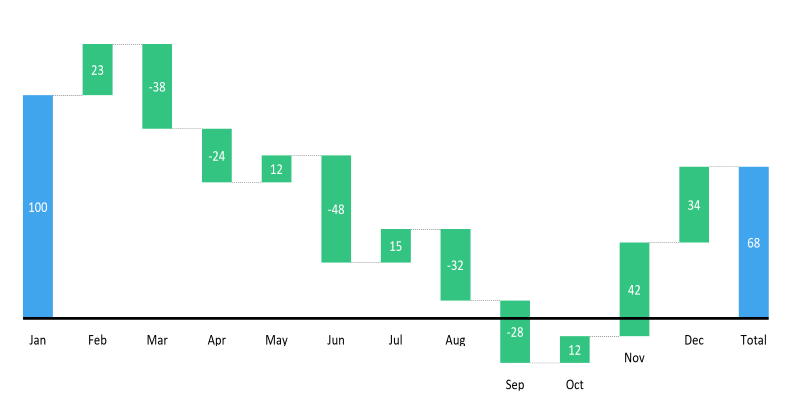
Learn how to create a waterfall chart in Excel, from setting up your data to formatting totals and customizing your chart for better clarity in reports
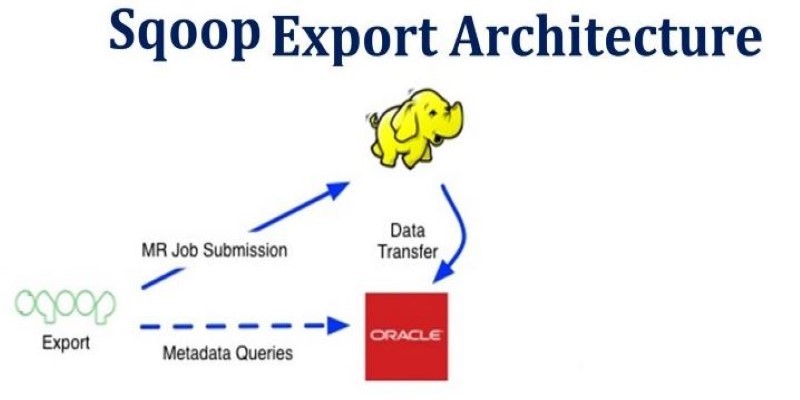
How Apache Sqoop simplifies large-scale data transfer between relational databases and Hadoop. This comprehensive guide explains its features, workflow, use cases, and limitations
How Hugging Face Accelerate works with FSDP and DeepSpeed to streamline large-scale model training. Learn the differences, strengths, and real-world use cases of each backend

Learn the top eight impacts of global privacy laws on small businesses and what they mean for your data security in 2025.

Which data science companies are actually making a difference in 2025? These nine firms are reshaping how businesses use data—making it faster, smarter, and more useful

How the EV charging industry is leveraging AI to optimize smart meter data, predict demand, enhance efficiency, and support a smarter, more sustainable energy grid

Discover 26 interesting ways to use ChatGPT in daily life—from learning new skills and writing better content to planning trips and improving productivity. This guide shows how this AI tool helps simplify tasks, boost creativity, and make your workday easier

Explore the role of a Director of Machine Learning in the financial sector. Learn how machine learning is transforming risk, compliance, and decision-making in finance

How the ORDER BY clause in SQL helps organize query results by sorting data using columns, expressions, and aliases. Improve your SQL sorting techniques with this practical guide
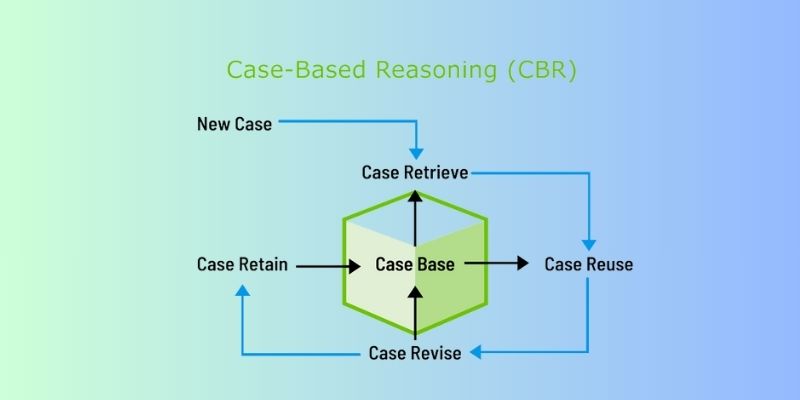
Discover how Case-Based Reasoning (CBR) helps AI systems solve problems by learning from past cases. A beginner-friendly guide

Google's Willow quantum chip boosts performance and stability, marking a big step in computing and shaping future innovations