Advertisement
MobileNetV2 sounds complex, but its purpose is simple. It's a small and efficient neural network designed for smartphones and edge devices. When you use a photo app that identifies objects or sorts pictures by faces, MobileNetV2 or a model like it may be doing the work. Large AI models need powerful machines, but MobileNetV2 was built for lean performance without relying on the cloud. It keeps things fast and accurate on limited hardware. In this article, we’ll explain how it works, why it’s effective, and where it’s commonly used.
MobileNetV2 is a type of convolutional neural network introduced by Google in 2018. It was built to improve on the original MobileNet by making it faster and more accurate, especially for mobile devices. The original goal was to allow modern AI to run smoothly on phones and embedded systems without requiring cloud servers or high-end GPUs.
While traditional deep learning models are large and resource-heavy, MobileNetV2 is designed to be light. It uses fewer calculations and has fewer parameters while staying close to the accuracy of bigger models. This makes it useful in real-time apps where slow processing and high battery use are not acceptable.
Its design allows for a good trade-off between speed and performance. It’s not meant to replace powerful models like ResNet or Inception but to fill a different need—fast, local inference on devices that can’t support bulky models.
MobileNetV2 uses clever techniques to keep the model small and quick. One of the main ones is depthwise separable convolution. In a normal convolutional layer, both spatial filtering and combining happen in a single step. But in MobileNetV2, these steps are separated. First, it filters the image data channel by channel and then combines them. This approach reduces the amount of computation needed.
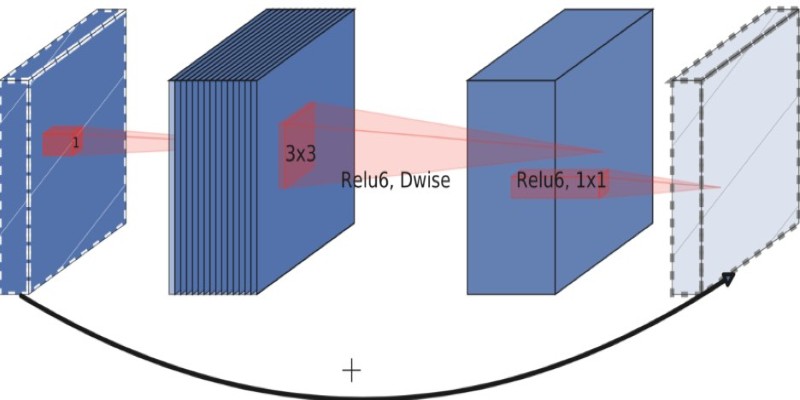
Another major feature is the inverted residual block. In standard neural networks, the structure usually narrows as it goes deeper. In MobileNetV2, this is reversed. The input first expands to a higher-dimensional space, is processed, and then shrinks again. This may sound backward, but it helps retain information while staying efficient.
It also replaces some nonlinear layers like ReLU with linear bottlenecks. Nonlinearities can destroy useful information in low-dimensional spaces. By using linear layers instead, the model holds on to more data while still reducing complexity.
These design tweaks allow MobileNetV2 to do a lot with little memory. It's fast and energy-efficient, yet flexible enough to be used for many computer vision tasks. It can be trained on different datasets and adapted to new use cases without needing to start from scratch.
The architecture of MobileNetV2 consists of multiple inverted residual blocks. Each block includes a 1x1 pointwise convolution to increase the number of channels, a 3x3 depthwise convolution to process spatial features, and another 1x1 pointwise convolution to compress the output. A skip connection is added if the input and output sizes match, which helps prevent data loss.
This structure repeats several times, creating a deep but efficient network. The model begins with a standard convolutional layer to handle the input, then goes through many inverted residual blocks, and finally ends with a few dense layers to make predictions.
MobileNetV2 typically uses about 3.4 million parameters and needs around 300 million multiply-add operations. That’s small compared to models like VGG16 or ResNet50, which can require over 100 million parameters.
It also supports different input image sizes. While 224x224 is common, the model can be adjusted to accept smaller sizes to run even faster. The width of the network can also be scaled using a parameter called the width multiplier. This allows developers to tune the model’s size based on the hardware it will run on.
Another helpful feature is quantization. This means converting the model from 32-bit floating-point numbers to 8-bit integers. It doesn’t affect accuracy much but cuts memory use and speeds up processing. Many mobile deployments use quantized MobileNetV2 models to save space and energy.
MobileNetV2 is used across many industries because of its small size and decent accuracy. One of the most common use cases is image classification on mobile apps. These apps can detect animals, food, text, and other categories instantly, even offline.

It's also used in face detection and recognition, particularly in phones. Some camera apps use MobileNetV2 variants to identify faces, organize albums, or unlock the screen using facial features. Since the model is efficient, it works well without draining the battery or needing a network connection.
In edge computing, MobileNetV2 powers devices like home security cameras, wearable gadgets, and smart sensors. These devices often can’t connect to the cloud for every task, so running AI locally is important. MobileNetV2 gives them the ability to process visual information on-device.
Developers also rely on it as part of TensorFlow Lite, a library for running models on mobile and IoT devices. TensorFlow Lite includes optimized versions of MobileNetV2 that are easy to drop into Android or embedded projects.
Even in research, MobileNetV2 is a common baseline for testing model compression and training methods. Its simple and well-documented architecture makes it useful for experiments, especially those focused on AI in low-resource settings.
Many smart applications use it in ways that are invisible to users. From scanning receipts to recognizing gestures in games or AR apps, MobileNetV2 plays a silent but important role.
MobileNetV2 shows that smaller doesn't mean weaker. With a smart design and efficient use of resources, it manages to perform complex visual tasks on devices most people carry in their pockets. It's not trying to beat the biggest models but to make deep learning usable where power and speed are limited. Whether it's sorting images, unlocking a phone, or helping a drone navigate, MobileNetV2 handles the job without overkill. This balance of speed, size, and accuracy is what keeps it relevant in AI development today.
Advertisement

Understand how GPT's decoder-only transformer works, its advantages, challenges, and why it is transforming the future of AI

Know how to reduce algorithmic bias in AI systems through ethical design, fair data, transparency, accountability, and more
How the hill climbing algorithm in AI works, its different types, strengths, and weaknesses. Discover how this local search algorithm solves complex problems using a simple approach

Learn the top eight impacts of global privacy laws on small businesses and what they mean for your data security in 2025.

How the semi-humanoid AI service robot is reshaping commercial businesses by improving efficiency, enhancing customer experience, and supporting staff with seamless commercial automation

How to Integrate AI in a Physical Environment through a clear, step-by-step process. This guide explains how to connect data, sensors, and software to create intelligent spaces that adapt, learn, and improve over time

Looking for faster, more reliable builds? Accelerate 1.0.0 uses caching to cut compile times and keep outputs consistent across environments

What a Director of Machine Learning Insights does, how they shape decisions, and why this role is critical for any business using a machine learning strategy at scale

Which data science companies are actually making a difference in 2025? These nine firms are reshaping how businesses use data—making it faster, smarter, and more useful

What happens when an automaker lets driverless cars loose on public roads? Nissan is testing that out in Japan with its latest AI-powered autonomous driving system

Looking for a reliable and efficient writing assistant? Junia AI: One of the Best AI Writing Tool helps you create long-form content with clear structure and natural flow. Ideal for writers, bloggers, and content creators

How using Hugging Face + PyCharm together simplifies model training, dataset handling, and debugging in machine learning projects with transformers