Advertisement
Imagine being able to describe what's in a photo the same way you'd talk to a friend. Not just pointing out "a dog" or "a car," but understanding the scene's relationships, context, actions, and even subtle emotional cues. That's where vision language models (VLMs) are headed. They're not just about recognizing shapes or reading words—they're learning to do both together and in real time. This shift shapes how machines interpret the world in a way that looks less like code and more like thought. And the pace of change isn't slowing down.
At the center of every VLM is pairing two traditionally separate AI tasks: computer vision and natural language processing. These systems are designed to take in visual input—photos, videos, or even live feeds—and connect it to natural language, producing descriptions, answering questions, or reasoning about the content.
The earliest efforts were mostly bolt-ons: vision systems fed data into language models that did their best to turn it into words. But that led to problems with coherence, ambiguity, and relevance. Modern models like CLIP, BLIP, and Flamingo don't just translate pictures into words—they learn to associate them deeply. A cat isn't just a shape with ears and fur; it's understood as sitting on a couch, watching a bird, or looking sleepy in the sunlight.
Training these models involves pairing huge amounts of images with captions or related text—think social media posts, websites, or curated datasets. They’re also increasingly trained on more complex tasks, such as image-grounded dialogue or storytelling. These methods teach models what things are and how to talk about them in ways that make sense to humans.
The newer wave of VLMs is dramatically more capable. One reason is that they're trained on more diverse, multimodal data. They're not just reading labels or descriptions—they're processing conversations, context, and nuance. This exposure teaches them how to move from object recognition to contextual understanding.

Another key improvement is in fine-tuning. Models now go through post-training stages, which are refined using smaller, high-quality datasets or guided with human feedback. This creates more accurate, context-aware responses. You can show a modern VLM a picture of someone pouring water into a glass and ask, "What happens next?"—and it might answer with, "The glass will fill up," or even, "If it overflows, the table might get wet." These aren't just correct—they're the answers people give.
Efficiency is also a big part of what makes them better. Older models took significant time and resources to analyze images. The newest systems use more streamlined architectures like transformers and attention mechanisms to process visual and language data faster and in parallel. This not only reduces response time but also improves overall accuracy.
Speed in VLMs isn’t just about how quickly they return answers. It’s about how rapidly they adapt, learn, and improve. With new training frameworks and model architectures, the lag between research breakthroughs and usable tools is shrinking. Few-shot and zero-shot learning mean these systems can perform new tasks without extra training. You show them a few examples, sometimes none, and they can generalize.
The rise of foundation models has been a major factor. These are large, pre-trained models that serve as a base for various downstream tasks. Instead of training a new model from scratch every time, developers can fine-tune an existing foundation model for specific applications. This massively reduces development time and costs.
There's also faster inference. Modern VLMs run faster without sacrificing quality thanks to improvements in hardware, model optimization, and quantization techniques. This matters in areas like autonomous vehicles or wearable tech, where real-time processing is key. If a car's onboard AI can process a street scene and deliver a judgment call within milliseconds, the technology becomes more viable in the real world.
When we talk about strength in VLMs, we usually refer to their flexibility, reliability, and problem-solving abilities. The best models today don’t just identify what’s in front of them—they can reason about it. They understand not just what things are but what they're doing, why it matters, and how they relate to each other.

This includes advanced capabilities like visual question answering, image captioning, and storytelling. For example, give a strong VLM an image of a crowded subway station, and it won't just say "people standing." It can describe the time of day, deduce the weather based on coats or umbrellas, and even guess people's likely destinations or emotional states.
Their strength also comes from robustness. In the past, minor changes to an image—different lighting, occlusions, or unusual angles—could confuse models. Training on diverse data has made them more tolerant of such variations. They're also less likely to be misled by visual illusions or misleading inputs.
Multimodal grounding plays a big part here, too. Strong VLMs don't rely solely on the image or the text. They draw meaning from both, cross-checking the content to reduce errors. This helps them avoid false assumptions and produce more coherent outputs.
Some of the most advanced models show early signs of reasoning and planning. They can be prompted to describe what they see, what could happen next, or how to solve a given task in the visual world. This opens the door to smarter digital assistants, automated inspection tools, and more helpful accessibility features.
Vision language models are evolving into tools that understand images and language with increasing accuracy and speed. They're not just faster but more intuitive, context-aware, and practical in everyday use. With better training and smarter design, these models can handle complex tasks and deliver meaningful results. As development continues, they're set to become a reliable part of daily interactions with technology.
Advertisement

Explore how generative AI transforms content, design, healthcare, and code development with practical tools and use cases

Discover 26 interesting ways to use ChatGPT in daily life—from learning new skills and writing better content to planning trips and improving productivity. This guide shows how this AI tool helps simplify tasks, boost creativity, and make your workday easier
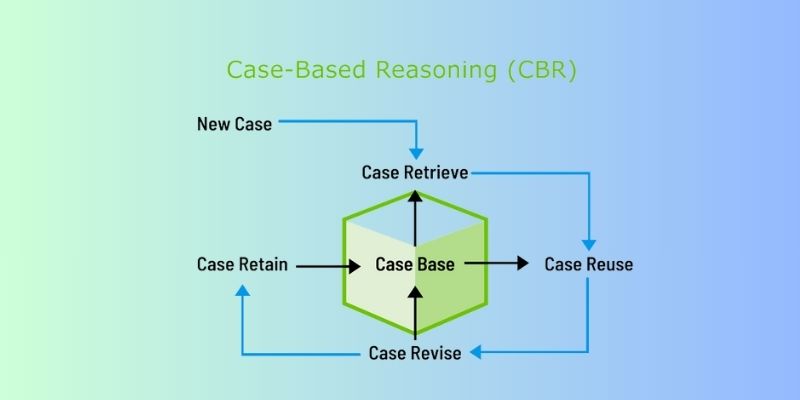
Discover how Case-Based Reasoning (CBR) helps AI systems solve problems by learning from past cases. A beginner-friendly guide

How the semi-humanoid AI service robot is reshaping commercial businesses by improving efficiency, enhancing customer experience, and supporting staff with seamless commercial automation

How AI is shaping the 2025 Masters Tournament with IBM’s enhanced features and how Meta’s Llama 4 models are redefining open-source innovation

Know how to reduce algorithmic bias in AI systems through ethical design, fair data, transparency, accountability, and more

Why is Alibaba focusing on generative AI over quantum computing? From real-world applications to faster returns, here are eight reasons shaping their strategy today
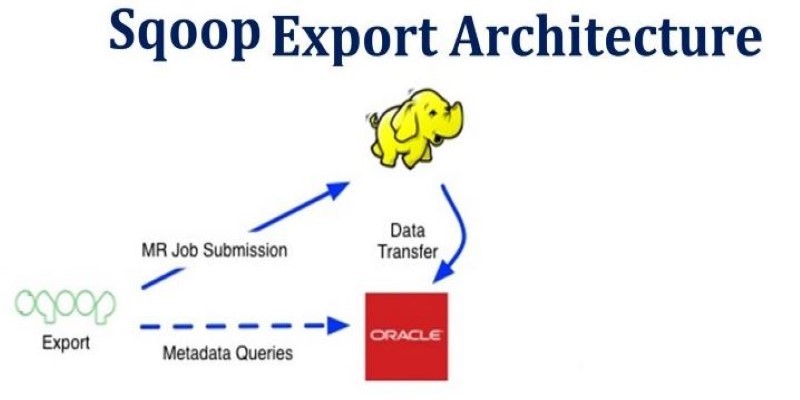
How Apache Sqoop simplifies large-scale data transfer between relational databases and Hadoop. This comprehensive guide explains its features, workflow, use cases, and limitations

Llama 3.2 brings local performance and vision support to your device. Faster responses, offline access, and image understanding—all without relying on the cloud

How the ORDER BY clause in SQL helps organize query results by sorting data using columns, expressions, and aliases. Improve your SQL sorting techniques with this practical guide

How to Integrate AI in a Physical Environment through a clear, step-by-step process. This guide explains how to connect data, sensors, and software to create intelligent spaces that adapt, learn, and improve over time
How Hugging Face Accelerate works with FSDP and DeepSpeed to streamline large-scale model training. Learn the differences, strengths, and real-world use cases of each backend