Advertisement
AI used to be something you interacted with from a distance—servers handling your requests, models running in data centers, everything tucked far away. That’s changing fast. With Llama 3.2, Meta’s latest language model, the experience is now much closer to home—literally. For the first time, Llama can run on your device, and this update doesn't stop there. It can now be seen as well. So yes, it's faster, more responsive, and far more capable than before.
But what does that actually mean in everyday use? Let’s take a closer look at what Llama 3.2 brings to the table, why local access matters, and how this new version steps things up by letting the model “see.”
Llama 3.2 is Meta's newest update, and even though the version number looks small, the features don't. It now has on-device support, so you can use it directly on your phone, laptop, or other device without relying on constant internet connectivity. The models are less heavy but no less robust, providing fast, snappy results without uploading your data to outside servers. This provides faster performance, more control, and better privacy.
The second big shift is vision support. Llama 3.2 can now understand images—charts, documents, photos, and more. It doesn't just recognize what’s there; it reads, interprets, and responds in context. Whether you need help with a menu, a form, or a screenshot, the model can break it down and explain it clearly.
Running models on your device isn't just about speed. It changes the way you interact with AI in three important ways.
When a model runs locally, your data doesn’t leave the device. There’s no upload, no processing on someone else’s server, and no unknowns about what happens after your prompt is sent. For sensitive content—whether that’s notes, personal images, or work-related documents—this is a welcome shift.
Llama 3.2 supports this kind of use natively. You can use it offline, and you can do so without worrying about where your data ends up.
Offline use isn't just about privacy. It's also about reliability. If you're in a location with spotty or no internet connection—on a plane, travelling, or just dealing with a service outage—you still have full access to the model. It performs locally and gives you the same quality responses without needing to connect to anything.
Cloud services come with a price. Whether that’s a subscription, API call charges, or data usage, the costs add up. Running a model on your device means you avoid all of that. You can use the model as often as you want without hitting a paywall or worrying about request limits.
A big part of what makes Llama 3.2 different is that it can now process images alongside text. That means you’re not limited to just asking questions or giving commands—you can now show the model what you're talking about. Here’s what that looks like in practice:

Take a photo of a document, and Llama 3.2 can tell you what it says. It doesn’t just do OCR—it gives you a structured response. You can ask it to summarize the contents, extract key points, or answer specific questions based on what’s written.
Point the model to a diagram or visual guide and ask it for help understanding it. Llama 3.2 doesn’t just describe what’s in the image—it interprets what’s happening and relates it to your prompt. It’s not just identifying items; it’s making sense of them.
You can use it to help identify places, objects, or text in photos you’ve taken—like signs in another language, handwritten notes, or visual data from your work. Its understanding isn’t pixel-deep; it’s meaning-driven.
So, how do you actually run Llama 3.2 locally? The process depends on your setup, but the general steps look something like this:

Llama 3.2 comes in different sizes, typically categorized by parameter counts, such as 8B or 4B. Smaller models are easier to run locally, especially on devices with limited memory or weaker processors. If you're working on a smartphone or older laptop, start with a lighter version.
To actually interact with the model, you’ll need a front-end or app that supports local LLMs. Tools like Ollama, LM Studio, or anything built with GGUF file support are good starting points. These interfaces help you load and talk to the model without writing code.
Once you’ve chosen your interface, download the model file (quantized versions are smaller and run faster) and load it through the app. Most tools will give you a simple way to do this—no command line required unless you prefer it that way.
If your interface supports it, try enabling vision features. Not all front-ends include this yet, but more are adding support over time. When available, you can upload an image along with your prompt and see how the model responds.
Once everything’s set up, you can interact with Llama 3.2 just like you would with any other assistant. Ask questions, generate content, summarize articles, or have it explain something from an image. The difference? It’s all happening locally.
Llama 3.2 isn’t just a small technical update. It’s a big move toward a more personal kind of AI—faster, more secure, and now capable of seeing what you show it. It works when you're offline. It keeps your data where it belongs. And it gives you new ways to interact by making sense of images and text together.
If you’ve been holding out for a reason to use a language model directly on your device, this version gives you that reason. And if you’re already using one, the new vision capabilities open up a lot more than just another input method—they offer a new way of understanding.
Advertisement

What happens when blockchain meets robotics? A surprising move from a blockchain firm is turning heads in the AI industry. Here's what it means

Know how to reduce algorithmic bias in AI systems through ethical design, fair data, transparency, accountability, and more

How the ORDER BY clause in SQL helps organize query results by sorting data using columns, expressions, and aliases. Improve your SQL sorting techniques with this practical guide

Artificial intelligence accurately predicted the Philadelphia Eagles’ Super Bowl victory while a quantum-enhanced large language model launched, showcasing AI’s growing impact in sports and technology

How Amazon is using AI to fight fraud across its marketplace. Learn how AI-driven systems detect fake sellers, suspicious transactions, and refund scams to enhance Amazon fraud prevention

How Orca LLM challenges the traditional scale-based AI model approach by using explanation tuning to improve reasoning, accuracy, and transparency in responses

If you want to assure long-term stability and need a cost-effective solution, then think of building your own GenAI applications
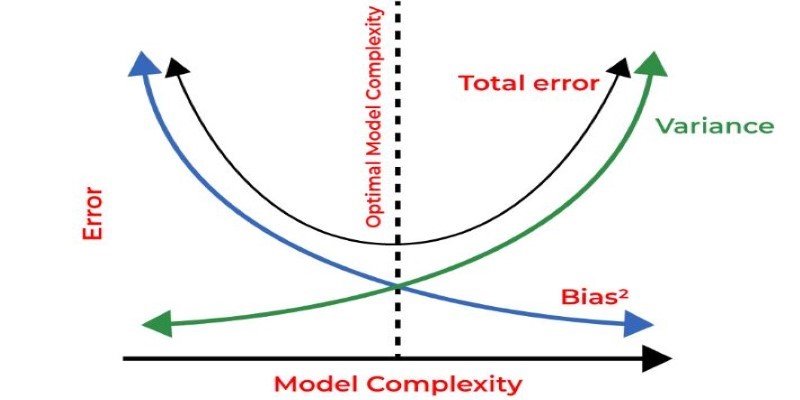
How regularization in machine learning helps prevent overfitting and improves model generalization. Explore techniques like L1, L2, and Elastic Net explained in clear, simple terms

Thinking about upgrading to ChatGPT Plus? Here's an in-depth look at what the subscription offers, how it compares to the free version, and whether it's worth paying for

Llama 3.2 brings local performance and vision support to your device. Faster responses, offline access, and image understanding—all without relying on the cloud

How the Vertex AI Model Garden supports thousands of open-source models, enabling teams to deploy, fine-tune, and scale open LLMs for real-world use with reliable infrastructure and easy integration
How the hill climbing algorithm in AI works, its different types, strengths, and weaknesses. Discover how this local search algorithm solves complex problems using a simple approach